This blog post demonstrates the techniques discussed in this paper for the NeurIPS 2020 Workshop on Machine Learning for Creativity and Design. Code can be found in this repository.
In short, the goal is to create convincing audiovisual latent interpolations by mapping audio features to the various inputs of the StyleGAN(2) generator. The main contributions are: chromagram-weighted latent sequences, applying different noise reactions to separate areas of the video, using network bending and model rewriting, and leveraging multiple levels of StyleGAN’s hierarchical architecture.
All of the audio processing discussed can be done with libraries like librosa or madmom.
Musical Features
Chromagram
The first thing you hear when listening to a song is its pitch. One representation of this is the chromagram. A chromagram divides the frequency spectrum into categories by pitch, for example, into the 12 notes of the western musical scale. This gives 12 separate envelopes which are high when that note is being played and low when it is not. Each envelope can be mapped to a different latent vector (any latent vector will do, of course, careful selection can greatly improve results). Taking the weighted sum of these latent vectors creates output images which vary according to the notes being played at the time.
StyleGAN’s hierarchical decoupling of image information allows for separate control of the high-level structure of the image and its color/details. Here we filter out the bass and chords separately and map their chromagrams to different sets of latent vectors. The bass latents control the lowest layers of StyleGAN (the general shape of the image) while the chord latents control the higher layers (the color and details).
Onset Envelope
Another important feature of music is its rhythm. The onset envelope of audio represents changes in the frequencies which are present in the signal. When there are large, sudden changes, the onset is high and when there are slow changes, it is low. This is one of the most visually obvious ways to let video react to audio.
In the following video, the kick and snare drums have been filtered out of the signal and their onsets calculated separately. The kick’s onset is mapped to the amplitude (standard deviation) of the noise, while the snare’s onset modulates between two different latent vectors.
Adding the drum modulations to the chromagram-weighted latents gives a decent baseline, audio-reactive video. Here the harmonic and percussive content have to be separated to calculate the onsets and chromagrams faithfully. Otherwise, the atonal, transient drum signals would show as if all 12 notes are played at once for a short moment (which could actually be an interesting effect, of course). Luckily, harmonic-percussive source separation is a well studied problem and both librosa and madmom have ready-to-use algorithms for this.
Beyond Latents
As more elements are added to the song, using only latent and noise controls starts to seem cluttered—even when modulating at multiple different levels in the hierarchy. At a certain point there are too many musical features competing to modulate the same group of latent and noise inputs. To alleviate this, a couple of techniques can be used which are easy to distinguish from transformations of latents or noise. This increases the “audio-reactive bandwidth” of the interpolation.
Spatial Noise
The noise inputs to StyleGAN are two-dimensional and so can be crafted such that reactions to different musical features occur in different parts of the image. Here a noise map is generated manually (left) and fed to StyleGAN at all levels.
Applying masks to musical features that modulate noise allows for separating musical information spatially. This can help increase clarity of reactions.
Network Bending
Broad et al. introduce a technique to manipulate the generated images called network bending. This works by applying transformations to the internal features partway through the network and then passing the modified features to the next layer. In the following video, the kick and snare drums are mapped to zoom and translation transformations. This frees the noise maps to be modulated by the new melody line that comes in halfway.
Here, only simple transformations are used, but Broad et al. describe ways to classify individual features in each layer to manipulate specific semantic aspects of the image (e.g. only the eyelashes of a model trained on faces).
Model Rewriting
A related technique called model rewriting (introduced by Bau et al.) works in a similar way but applies the transformations to the weights of the network.
Once again, only simple transformations are applied to the weights in this example (scaled by a normally distributed factor with mean -1), but Bau et al. introduce methods that find higher-level semantic transformations (e.g. transforming church domes to trees or adding hats to horses!).
Both network bending and model rewriting offer even more direct control over features in the images that are generated. This opens up a world of possibilities for visual features that can be modulated by the audio that are readily distinguishable from latent or noise interpolations.
Leveraging Musical Structure
So far, musical features the musical features we’ve discussed are low-level, short-timescale features. Another promising information source is the higher-level, long-timescale structure of the music. For example, different latents that convey different feelings could be used for different sections.
There are a couple ways to distinguish between sections, the most naive being annotating them manually. Here I’ll discuss a few more possibilities that aren’t manual.
Once different sections are recognized, latents, noise, and manipulations can be customized to fit each part and then spliced together.
RMS
A decent heuristic for section analysis is the moving average of the Root Mean Squared (RMS) of the audio signal. The chorus or drop section of a song might have more instruments or just be louder in general. This means the RMS will correlate with the energy of the song.
Below, the smoothed RMS of the bass (which is only present in the main section of the song) is used as an envelope that mixes between two sets of chromagram-weighted latents: warm colors for the intro/outro and cool colors for the main section.
N.B. the 1920x1080 resolution is achieved with a little network bending trick. Applying a mirroring transformation on the learned constant layer (lowest layer in the generator) doubles the width. This propagates all the way up through the fully-convolutional network leaving an output with twice the width.
Laplacian Segmentation
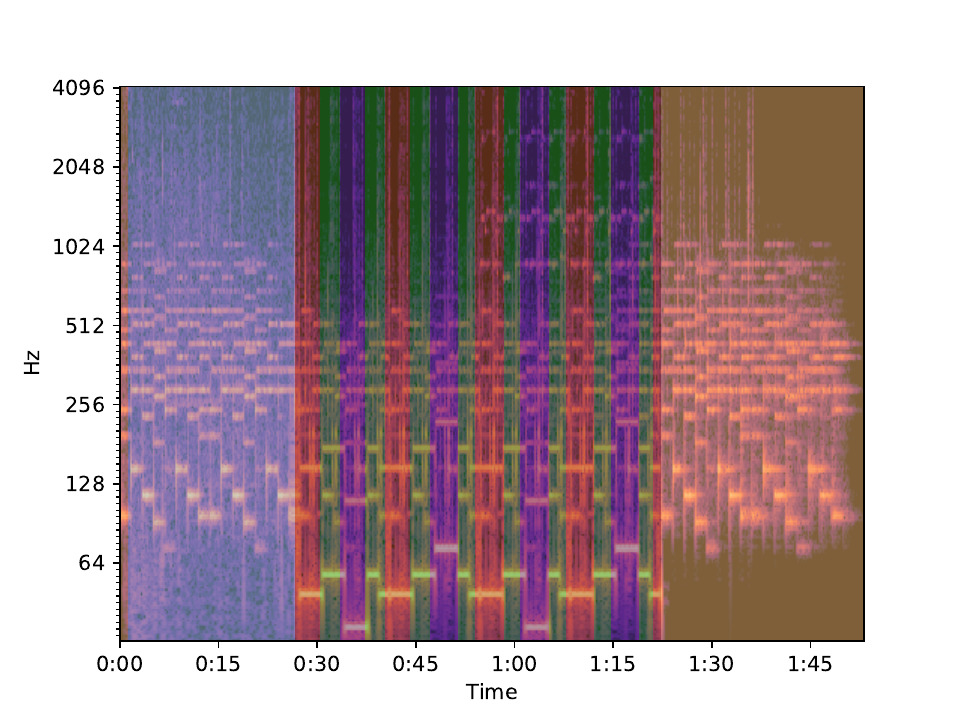
Another option is laplacian segmentation. This algorithm analyzes the repeated hierarchical pattern structure of music to determine different sections.
Below is the spectrogram of the song from the previous video. The overlayed colors represent the different labels that laplacian segmentation has assigned to the sections. Different interpolations can be generated for each label and then spliced together according to each label’s timestamps.
Repetition
The techniques discussed so far require careful fine-tuning of multiple parameters for the best result (e.g. audio filtering cutoffs, modulation strength, weighting of latents, standard deviation of noise, amplitude smoothing, etc.). This provides great creative control, but requires time and effort to perfect. There are also some simpler techniques which provide decent results on a variety of inputs with comparatively less fine-tuning required.
One important quality of music (especially dance music) is repetition. Songs are built from patterns that repeat and shift in fixed intervals. This varies from song to song, of course, but a simple way to have the video change in time with the music is to loop latent or noise interpolations in 4, 8, or 16 bar intervals.
Simply adding the onset envelope of the percussive elements of the entire song to modulate noise with alongside these latent loops creates a convincing audiovisual interpolation.
The following video for a 30 minute DJ mix was generated using this approach. Rather than using automatic section analysis, timestamps of transitions were entered manually to switch between latent vectors which were selected for each song. A moving average of the RMS was used to mix between faster latent loops and higher standard deviation noise during the high energy sections and less intense latents/noise in the softer sections.
Closing Thoughts
StyleGAN’s hierarchical, learned representation provides rich control of the generation of images. Using basic signal processing and music information retrieval techniques, this control can be leveraged to generate latent interpolations that react to the music.
As more techniques like network bending and GAN rewriting are developed, the possibilities for creative expression using generative models will continue to grow.
In the future better heuristics and techniques to extract information from the music will help reduce the fine-tuning required and improve responsiveness even more.
Where previously artists would have to program a rich generative/procedural system manually, now GANs can be trained to learn semantic representations of arbitrary image data. This will allow people without extensive knowledge of visual design programs or music information retrieval to create audio-reactive videos more easily.